
연산이 아닌 메모리의 문제: PIM-GPT가 보여준 LLM 하드웨어의 방향

Summary
- GPT와 같은 자기회귀(Autoregressive) 모델은 연산량보다 ‘메모리 접근’에서 병목이 발생하며, 이 때문에 기존 GPU 자원을 생각보다 훨씬 비효율적으로 사용합니다.
- PIM-GPT는 메모리(DRAM) 내부에서 행렬 곱을 수행하고, 단순화된 보조 칩(ASIC)이 나머지 연산을 맡는 구조로 데이터 이동을 최소화합니다.
- 연산 칩의 클럭을 10분의 1로 낮춰도 성능 저하가 거의 없다는 결과는, LLM 추론에서 진짜 중요한 것은 ‘얼마나 빨리 계산하느냐’가 아니라 ‘데이터가 어디에 있느냐’임을 보여줍니다.
- 하드웨어 효율을 높이기 위해 도입한 수학적 근사 연산이 긴 문맥 생성에서 품질 저하로 이어질 가능성, 그리고 1.4B 이상 초거대 모델에 대한 확장성 검증이 빠져 있다는 점은 아쉬운 부분입니다.
- LLM 추론 하드웨어 전략은 이제 TFLOPS 경쟁이 아니라, 메모리와의 물리적·구조적 거리를 줄이는 방향으로 전환되어야 합니다.
연산 속도보다 데이터 이동이 지배하는 시대
PIM-GPT 관련 논문이 있습니다.
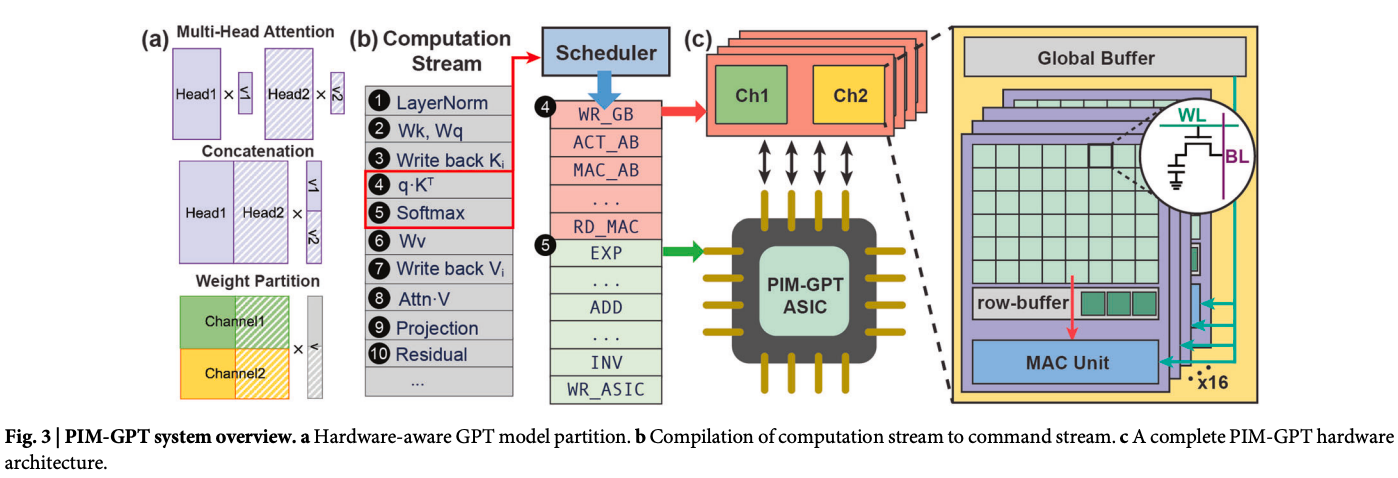
PIM-GPT는 ‘메모리 월(Memory Wall)’ 문제를 정면으로 겨냥한 하이브리드 가속기입니다. 논문에서는 속도와 에너지 효율 개선을 강조하지만, 그 이면에는 더 흥미로운 메시지가 숨어 있습니다.
첫째, ASIC의 클럭을 1GHz에서 100MHz로 10배 낮춰도 전체 성능 저하는 최대 20%에 그쳤습니다. 이건 꽤 상징적입니다. GPT 추론이 본질적으로 연산 병목이 아니라 메모리 병목이라는 사실을 정면으로 보여주기 때문입니다. 빠른 연산 유닛을 더 얹는다고 해결될 문제가 아니라는 이야기입니다.
둘째, 기존 폰 노이만 구조처럼 데이터를 연산기로 끌어오는 대신, 연산을 데이터가 있는 DRAM Bank 안으로 밀어 넣자 I/O 에너지가 전체의 10% 미만으로 떨어졌습니다. 결국 전력도, 지연도, 비용도 데이터 이동이 지배하고 있었다는 뜻입니다.
셋째, 모든 연산을 메모리 안에 욱여넣지 않고, 비선형 연산은 별도 ASIC으로 분리한 설계는 현실적인 선택입니다. PIM 기술에 대한 과한 이상주의 대신, “어디까지를 메모리에서 처리할 것인가”라는 실용적 균형점을 찾았다고 볼 수 있습니다.
PIM-GPT의 타협과 내재된 모순
논문은 “정확도 손실 없이(without accuracy loss)” 유연성을 확보했다고 말합니다. 하지만 설계 내부를 보면 긴장 지점이 분명히 존재합니다.
가장 큰 충돌은 ‘정확성’과 ‘효율성’ 사이의 균형입니다. Softmax, LayerNorm, GELU 같은 비선형 함수는 테일러 급수나 뉴턴-랩슨 근사법으로 계산됩니다. BF16 환경에서 반복 횟수를 최소화해 면적과 전력을 아끼는 구조입니다. 합리적인 선택입니다. 다만 근사 연산은 결국 오차를 남깁니다.
문제는 LLM의 자기회귀 특성입니다. 한 토큰의 미세한 오차가 다음 토큰으로 이어지고, 그 다음으로 또 이어집니다. 수천 토큰을 생성하는 과정에서 이 오차가 누적될 때, 과연 “정확도 손실 없음”이라는 표현이 얼마나 유지될 수 있을까요?
이 질문은 아직 충분히 답을 얻지 못했습니다. 하드웨어 가속기 설계에서 피할 수 없는 ‘정확도-성능 트레이드오프’가 그대로 드러나는 지점입니다.
초거대 모델과 실제 생성 품질
이 연구는 인상적이지만, 중요한 공백도 있습니다.
첫째, 검증된 최대 모델은 1.4B 파라미터 수준입니다. 오늘날 산업 현장에서 다루는 모델은 수십억을 넘어 수백억 파라미터 규모입니다. 멀티노드 환경에서 통신이 개입될 경우, PIM 구조의 이점이 그대로 유지될지에 대한 실증은 제시되지 않았습니다.
둘째, 실제 생성 품질에 대한 평가는 거의 없습니다. 지연 시간과 에너지 수치는 충분히 분석되었지만, 생성된 텍스트의 Perplexity나 장문 생성 품질이 GPU 기반 환경과 동일한지에 대한 비교는 빠져 있습니다.
성능 그래프는 설득력이 있습니다. 하지만 “결과물의 품질은 동일한가?”라는 질문에는 아직 답이 필요합니다.
TFLOPS의 환상에서 벗어나라
실무자나 인프라 의사결정자가 가져가야 할 메시지는 단순합니다.
LLM 실시간 추론 서비스에서는 GPU의 TFLOPS 수치에 집착하는 전략이 점점 의미를 잃고 있습니다. 작은 배치 사이즈 환경에서는 연산 유닛 상당수가 놀게 됩니다. 진짜 비용은 가중치를 메모리에서 끌어오는 데서 발생합니다.
앞으로의 하드웨어 전략은 “더 빠른 코어”가 아니라 “더 짧은 데이터 경로”에 초점을 맞춰야 합니다. PIM과 같은 메모리 중심(Memory-centric) 접근은 그 방향을 가장 직관적으로 보여줍니다.
Conclusion
제가 이 글에서 강조하고 싶었던 핵심은 하나입니다. 생성형 AI 시대의 병목은 컴퓨팅이 아니라 메모리에 있다는 점입니다.
PIM-GPT는 연산을 메모리 옆으로 옮기는 것만으로도 에너지 효율과 지연 측면에서 큰 개선이 가능하다는 것을 보여주었습니다. 물론 초거대 모델 확장성과 근사 연산의 장기적 품질 영향이라는 과제는 남아 있습니다.
그럼에도 불구하고 방향은 분명합니다. AI 가속의 미래는 연산기를 더 크게 만드는 경쟁이 아니라, 데이터가 머무는 자리에서 조용히 계산을 끝내는 아키텍처로 이동하고 있습니다.